Fusion methodology
A complete description of the fusionACS methodology is provided by Ummel et al. (2024). For a given donor survey, the data processing and analysis “pipeline” consists of the following steps:
- Ingest raw survey data to produce standardized microdata and documentation.
- Harmonize variables in the donor survey with conceptually-similar variables in the ACS.
- Prepare clean, structured, and consistent donor and ACS microdata.
- Train machine learning models on the donor microdata.
- Fuse the donor’s unique variables to ACS microdata.
- Validate the fused microdata.
- Analyze the fused microdata to calculate estimates and margins of error.
Steps 1–3 are part of the fusionData package, and Steps 4–6 are carried out using the fusionModel package. These steps are carried out by the fusionACS team internally, and there is generally no reason for a practitioner to use the associated packages.
The key functionality of Step 7 is provided by the fusionACS package documented on this site.
The figure below from Ummel et al. (2024) shows how the various input data sources fit together.
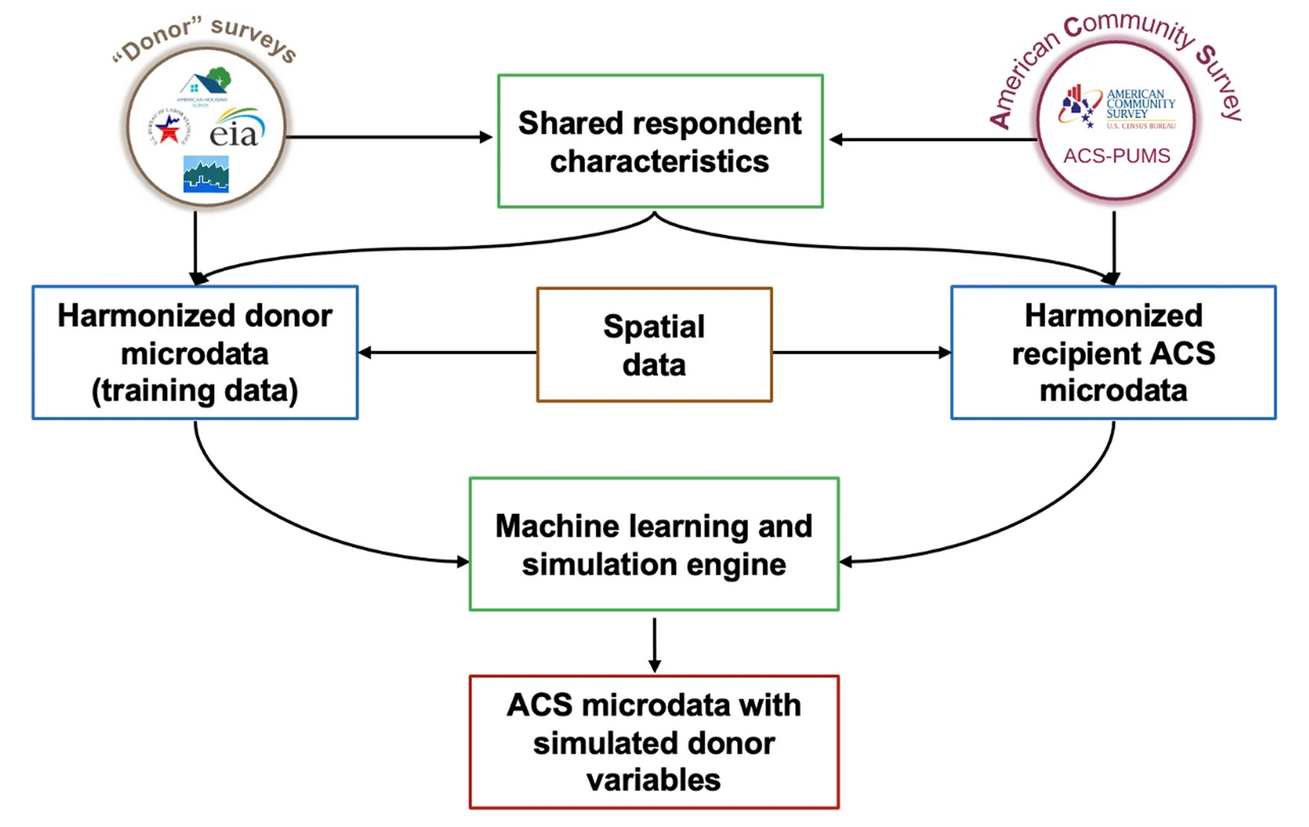
The spatial data consists of a wide range of place-specific predictor variables that can be merged to both donor and ACS microdata on the basis of respondent location. These are used to augment the harmonized, respondent-level predictors available to the machine learning models.
UrbanPop integration
Recent work integrating ORNL UrbanPop represents a significant advancement in the ability of fusionACS to generate high-resolution estimates across space.
UrbanPop is a synthetic population data product produced by Oak Ridge National Laboratory (Tuccillo et al. 2023). It provides probabilistic estimates of the location (block group) of each ACS respondent household. Specifically, for each block group, ACS PUMS respondent households are re-weighted to replicate published ACS Summary File tables for key demographic, economic, employment, mobility, and housing variables.
Merging fusionACS microdata with UrbanPop (linking on PUMS respondent ID) results in simulated block group populations for which we can observe both ACS and donor survey variables. This allows fusionACS + UrbanPop to generate estimates for geographic areas smaller than the Public Use Microdata Areas (PUMA’s) disclosed in the ACS PUMS.
Since UrbanPop assigns each ACS household to multiple block groups (about 8, on average) the merged microdata can become quite large. The public pseudo-sample includes only a partial, structured sample of the UrbanPop weights. This helps keep the public data release fully functional but also a manageable size. Analyses computed on the complete database inside the Yale High Performance Computing (HPC) facility utilize the complete UrbanPop dataset to derive production-level estimates.
Point estimates and uncertainty
A fusionACS analysis consists of a request for an estimate of a particular variable across one or more sub-populations. Estimates can be means, medians, sums, proportions, or counts. For example, “Mean household electricity consumption in Chicago, by census tract”; or “Proportion of low-income households in Atlanta without air conditioning”.
In addition to a point estimate, fusionACS also returns the associated uncertainty or margin of error. Uncertainty in the underlying machine learning models is captured through the production of M unique implicates (typically 20). Each implicate is a unique and equally-plausible simulation of the fused variables given uncertainty in the underlying fusion process. The public pseudo-sample includes only a single implicate (M=1).
By assessing the variance both within and across implicates, it is possible to calculate the margin of error associated with any given point estimate.
Pooled variance
For any given fusionACS analysis, the point estimates and associated margin of error are calculated using the technique of Rubin (1987). The point estimate, , is the mean of the individual estimates calculated for each of the implicates:
The variance of is calculated by “pooling” the variance both within and between samples:
where is the “between-sample” variance of the individual estimates:
and refers to the “within-sample” variances of the individual estimates; i.e. the square of the standard error [].
Within-sample standard errors
The calculation of within-sample standard errors depends on the type of estimate requested. To calculate the standard error of a mean estimate for a sample of observations with frequency weights :
where is the weighted mean and is the effective sample size calculated from the observation weights:
The observations weights either come
directly from the ACS PUMS or from ORNL UrbanPop, depending on the level
of geographic detail required by an analysis. By default,
assemble() automatically chooses the appropriate weights.
The public pseudo-sample includes only a partial, structured sample of
the UrbanPop weights.
The use of the “effective sample size” – rather than sample size – helps capture additional uncertainty in the sample weights themselves (Kish 1965; Lumley 2010). In general, the smaller the target population the greater the “unevenness” of the observed sample weights, leading to , and a corresponding increase in the standard error.
This approach differs from the “Successive Differences Replication” (SDR) method typically used to calculate the margin of error when working with the ACS PUMS (U.S. Census Bureau 2020). However, in initial testing we find that the SDR and effective sample size approaches yield very similar uncertainty estimates , with the latter exhibiting a slight upward bias. Since SDR requires significantly more computation, for the time being we have opted to use the effective sample size technique instead.
The implementation in R uses the collapse package
qsu() function (Krantz 2025), which computes the mean,
standard deviation, and sum of weights in a single pass through the data
in C/C++. This provides extremely fast calculation, even when the data
is grouped across
implicates and (optionally) user-specified sub-populations.
For median estimates, calculation of the standard error via bootstrapping is prohibitively expensive (Hahn and Meeker 1991). Given the need for computational efficiency in the fusionACS context, the standard error of the median is instead estimated using the large-sample approximation:
where is the density at the median. The formula arises from the asymptotic variance of sample quantiles under regularity conditions (Serfling 1980). For speed, is approximated using a finite difference of the quantile function (Koenker 2005):
where is the weighted quantile function, and and are probabilities close to the median (0.475 and 0.525, by default). Implementation via the collapse package leverages a single, radix-based ordering of the input to efficiently compute the median, , and . This allows the standard error to be estimated at little additional cost beyond computation of the median itself.
If is undefined, the code falls back to the conservative approximation of Tukey (1977):
To calculate the standard error of a proportion, given the previously-defined effective sample size:
where is the Agresti-Coull (Agresti and Coull 1998) adjusted proportion derived from the weighted sample proportion (), assuming a 90% confidence interval ():
This adjustment ensures a non-zero standard error when is zero; e.g. for unobserved outcomes in smaller samples. The un-adjusted sample proportion () is always returned as the point estimate.
For sums (numerical case) and counts (categorical case), the standard error is a multiple of the standard error of the mean and proportion, respectively:
Margin of error
Having calculated and its component variances, the degrees of freedom is calculated using the formula of Barnard and Rubin (1999). Compared to the original Rubin (1987) degrees of freedom, this formulation allows for unequal within-sample variances and is more accurate for small samples.
In keeping with the convention used by the U.S. Census Bureau for published ACS estimates, fusionACS returns the 90% margin of error:
Interpretation of uncertainty
There is no universal standard for judging when the margin of error and/or coefficient of variation are “too high”. The answer always depends on the nature of the analysis and intended application. At a minimum, generalized guidelines should be used to determine when and if valid conclusions can be drawn from specific estimates; for example, see Parmenter and Lau (2013), page 2.
It is important that analyses or reports based on fusionACS data products communicate the authors’ chosen standards for determining when an estimate is sufficiently reliable to draw conclusions.